SeimiCrawler+SeimiAgent完美解决动态页面渲染Ajax抓取问题
前言
曾几何时,动态页面(ajax,内部js二次渲染等等)信息提取一直都是爬虫开发者的心痛点,一句话,实在没有合适的工具。尤其在Java里面,像htmlunit这种工具都算得上解析动态页面的神器了,但是他依然不够完备,达不到浏览器级的解析效果,遇到稍微复杂点的页面就不行了。在经历的各种痛与恨后,笔者决定干脆开发一款专为应对抓取,监控,以及测试这类场景使用的动态页面渲染处理服务器。要达到浏览器级的效果,那必须基于浏览器内核来开发,幸运的是我们有开源的webkit,更为幸运的是我们有对开发者更为友好的QtWebkit。所以SeimiAgent就这样诞生了。
SeimiAgent简介
SeimiAgent是基于QtWebkit开发的可在服务器端后台运行的一个webkit服务,可以通过SeimiAgent提供的http接口向SeimiAgent发送一个load请求(需求加载的URL以及对这个页面接受的渲染时间或是使用什么代理等参数),通过SeimiAgent去加载并渲染想要处理的动态页面,然后将渲染好的页面直接返给调用方进行后续处理,所以运行的SeimiAgent服务是与语言无关的,任何一种语言或框架都可以通过SeimiAgent提供的标准http接口来获取服务。SeimiAgent的加载渲染环境都是通用浏览器级的,所以不用担心他对动态页面的处理能力。目前SeimiAgent只支持返回渲染好的HTML文档,后续会增加图像快照已经PDF的支持,方便更为多样化的使用需求。
使用演示
SeimiCrawler简介
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的Seimi帮你搞定。设计思想上SeimiCrawler受Python的爬虫框架Scrapy启发很大,同时融合了Java语言本身特点与Spring的特性,并希望在国内更方便且普遍的使用更有效率的XPath解析HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath(独立扩展项目,非jsoup自带),默认解析提取HTML数据工作均使用XPath来完成(当然,数据处理亦可以自行选择其他解析器)。
整合使用
部署SeimiAgent
下载解压缩就不表了,上面的动态图中也有演示,下载地址可以到SeimiAgent主页找到。进到SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这是启动SeimiAgent服务并监听8000端口。接下来实际上就可以使用任何语言通过http请求发送加载页面的请求,然后得到渲染后的结果。当然我们这里是要介绍SeimiCrawler是如何整合使用SeimiAgent的。
SeimiCrawler配置
SeimiCrawler在v0.3.0版本中已经内置支持了SeimiAgent,只需要开发者配置好SeimiAgent的地址和端口,然后在生成具体Request时选择是否要提交给SeimiAgent,并且指定如何递交。直接上个完整例子在注释中说明吧:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
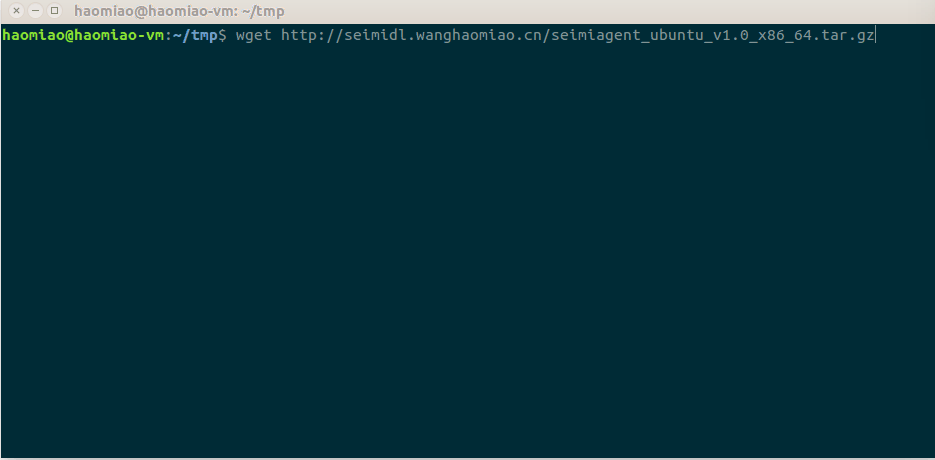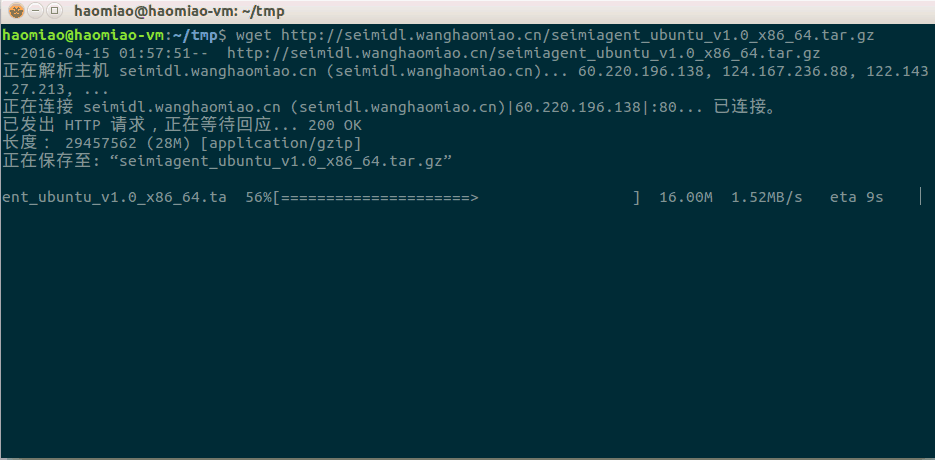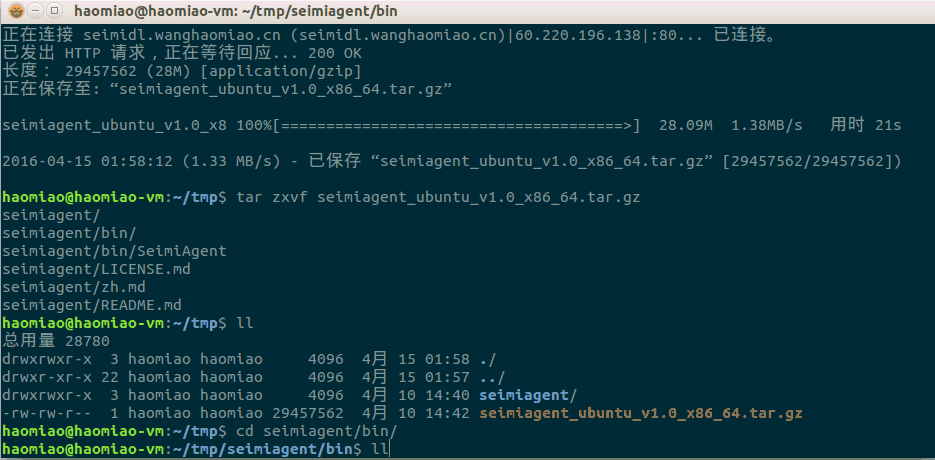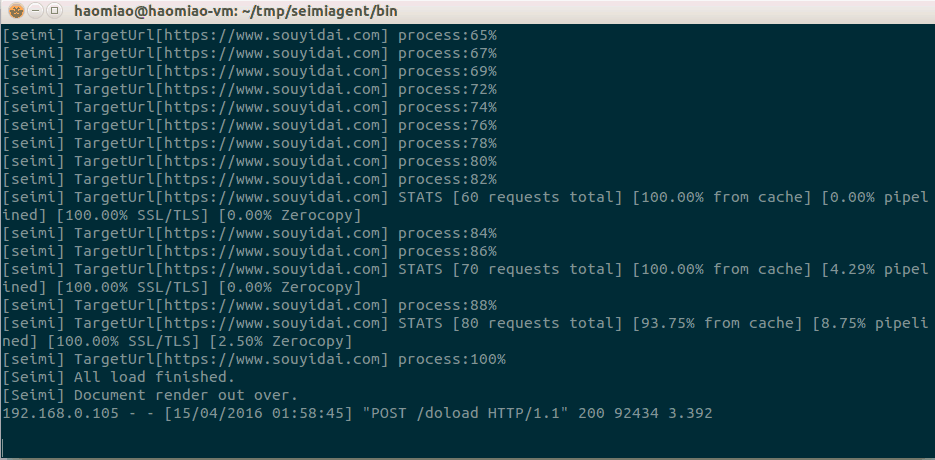
SeimiCrawler启动后就可以看到你想要的搜易贷交易总额了。